Counterfactual Q-Learning in Letter World
The Concept
Counterfactual Q-Learning leverages the structured nature of RM/CRMs to generate additional “what-if” experiences that the agent can learn from, without actually having to explore those states. By utilizing the symbolic representation in the CRM, we can:- Infer consequences of different actions
- Update multiple state-action values at once
- Accelerate learning significantly
Implementation Comparison
Let’s compare standard Q-Learning with Counterfactual Q-Learning in the Letter World environment.Standard Q-Learning
Counterfactual Q-Learning
The key difference is the addition of
generate_counterfactual_experience(), which provides additional learning signals without requiring actual exploration.Performance Comparison
When we run both algorithms on the Letter World environment, we see a significant improvement in learning efficiency with Counterfactual Q-Learning: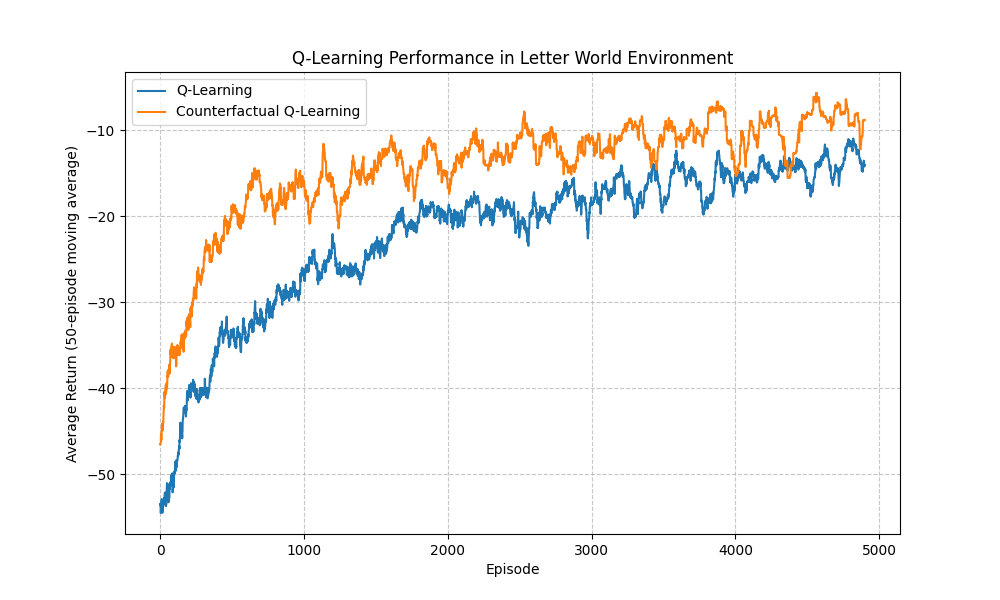
- Counterfactual Q-Learning (orange) learns much faster and achieves higher returns
- Standard Q-Learning (blue) requires many more episodes to approach similar performance
- Both eventually converge, but counterfactual learning requires significantly fewer samples
How It Works
The counterfactual learning process works through these steps:- The agent takes an action in the environment
- The CRM uses its symbolic structure to infer what would have happened for other state-action pairs
- These counterfactual experiences are used to update multiple Q-values simultaneously
- This process effectively multiplies the learning signal from each real experience
Code Breakdown: Generating Counterfactual Experiences
The magic happens in thegenerate_counterfactual_experience method:
Benefits and Applications
Counterfactual Q-Learning offers several advantages:- Sample Efficiency: Learns from fewer real-world interactions
- Faster Convergence: Reaches optimal policy more quickly
- Better Exploration: Effectively explores the state space
- Interpretability: Leverages symbolic structure of CRMs
- Exploration is expensive or risky
- Task structures have clear symbolic representations
- Sample efficiency is critical